Computer Science 461 - Fall 2023
Jump to week:
Week 1 Notes
| Mon, Aug 21 |
1.3 |
Proof techniques |
| Wed, Aug 23 |
2.1 - 2.2 |
Notation & encodings |
| Fri, Aug 25 |
3.1 - 3.7 |
Boolean circuits |
Monday, Aug 21
Today we talked about proof techniques, particularly proof by induction. We looked at these two examples:
- Prove that if a set has elements, then has subsets.
The second example had to do with the famous Tower’s of Hanoi puzzle( see https://youtu.be/SMleU0oeGLg).
- Use induction to prove that it is always possible to move the disks from one peg to another by moving one disk at a time without breaking the rules.
Wednesday, Aug 23
Today we reviewed mathematical notation, including some new notation we will be using. Then we talked about encoding a finite set using binary strings. We observed that every countable set can be encoded with a 1-to-1 function from . We discussed specific encodings such as how to encode the integers and the rationals .
At the end we considered the set which you can think of as the set of all infinitely long strings of zeros and ones. We claimed, but did not have time to prove that there is no 1-to-1 encoding function .
Friday, Aug 25
Today we finished the proof that there is no 1-to-1 encoding function from to .
Then we talked about Boolean circuits which are formed by AND, OR, and NOT gates.
Show that you can construction the function IF A THEN B ELSE C for any Boolean inputs A, B, C using AND, OR, and NOT gates.
Use mathematical induction to prove the following:
Theorem. Every function can be represented by a Boolean circuit.
We finished by talking about how NAND gates are also universal in the sense that any function that can be constructed from AND, OR, NOT gates can also be constructed with NAND gates.
Week 2 Notes
| Mon, Aug 28 |
|
Impossible computer programs |
| Wed, Aug 30 |
2.1 |
Intro to finite automata |
| Fri, Sep 1 |
2.2 - 2.3 |
Regular languages |
Monday, Aug 28
Today we talked about functions that cannot be computed by a computer program.
Wednesday, Aug 30
Today we introduced finite automata. We started with three examples:
An automatic door at a grocery store with sensors on the front and rear. It opens if the sensor on the front is active. It won’t close until neither of the sensors are active.
An automatic toll both that accepts nickles, dimes, and quarters. The gate won’t open until it receives 25 cents.
A combination lock needs three numbers entered correctly (in order) before it will open.
With these examples we introduced state diagrams, and the definition of a deterministic finite automata (DFA).
- Then we constructed a DFA that can compute the function which returns 1 when the input string has an odd number of 1’s and 0 otherwise.
Friday, Sep 1
Today we started with these questions about DFAs:
For the DFA shown below:
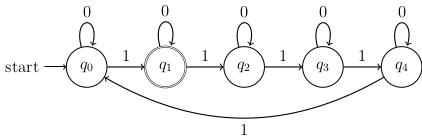
- What is the transition function?
- Describe the function that this DFA computes.
Draw the state diagram for a DFA that computes whether a binary string contains 011.
Modify the DFA from the last problem so that it computer whether a binary string ends with 011.
How many states would a DFA need if you wanted to check whether a binary string has a 1 in the third position from the last?
After we did these examples, we defined languages which are just subsets of strings in . Then we gave a recursive definition of regular languages and looked at some simple examples.
Week 3 Notes
| Wed, Sep 6 |
2.4 |
Nondeterministic finite automata |
| Fri, Sep 8 |
2.6 |
NFAs and regular languages |
Wednesday, Sep 6
Today we looked at an alternative definition of a regular language: A language is regular if and only if there is a DFA that accepts if and only if . To prove that this definition is equivalent to the one we gave last week, we need to prove three things:
The union of two regular languages is regular.
The concatenation of two regular languages is regular.
The Kleene star of a regular language is regular.
We proved #1 in class by thinking about how to construct a new DFA that accepts using DFAs and that accept and respectively. To prove this, we answered these questions:
If the machine is built by running both and simultaneously, what are the possible states of ?
What are the accepting states of ?
What are the initial states for ?
What is the transition function for ?
To prove that regular languages are closed under concatenation, we introduced a new idea: non-deterministic finite automata (NFAs).
We looked at this example:
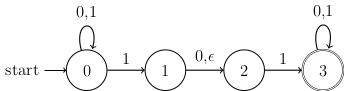
We answered these questions:
Which states are active at each step as we read the input string 010110?
Does this NFA accept the string 010110?
Describe the set of all strings in that this NFA will accept.
Friday, September 8
Today we continued talking about NFAs. We’ve been following the textbook by Meshwari & Smid pretty closely this week, so I strongly recommend reading skimming Section 2.6 which is what we covered today.
We started with some examples of NFAs.
Last week we talked about how many states a DFA would need to check if a string in has a 1 in its third to last entry. We saw that a DFA needs at least 8 states for that language. But an NFA can do the job with only four states. Try to construct an example. Hint: What if the NFA “guesses” every time it sees a 1 that that might be the third to last entry. What should it’s states be from that point on?
Construct an NFA that accepts a string in iff the length of the string is a multiple of 2 or 3. Can you construct a DFA that does the same thing and with the same number of states?
After these examples, we explained two important ideas:
You can easily construct an NFA to check if a string is in when and are regular languages.
It is also easy to check if when is a regular language.
For practice, see if you can construct an NFA that checks if when and are regular languages.
Week 4 Notes
| Mon, Sep 11 |
2.5 |
NFAs and DFAs are equivalent |
| Wed, Sep 13 |
2.7 - 2.8 |
Regular expressions |
| Fri, Sep 15 |
2.9 |
The pumping lemma |
Monday, September 11
Today we explained the surprising fact that any language an NFA can recognize can also be recognized by a DFA. The idea is to convert an NFA into a DFA which has states that are subsets of the states of , i.e., the states of are the power set of the states of . Then you have to make a transition function from sets of states to sets of states using the transition function .
We looked at this example (again) to see how the idea works:
Notice that this NFA starts at state 0, and no matter what input we receive, state 0 stays active. So there is no way to reach a set of active states that does not contain state 0. So that cuts the number of elements we need to worry about in by half.
We also talked about regular expressions.
Recursive Definition. A regular expression over an alphabet is a string with symbols from the extended alphabet that has one of the following forms:
- is a single symbol in .
- where and are regular expressions.
- where is a regular expression
- where is a regular expression
We also accept the empty set and the empty string "" as regular expressions.
Regular expressions are used to match sets of strings (i.e., languages over ). matches any string that is a concatenation of a string matched by with a string matched by . The regular expression matches anything matched by or . Finally matches any finite concatenation of strings that matches (including no repetitions).
Let . What strings does the regular expression pet(dog|cat) match?
What strings does the regular expression pet(dog|cat|bird)* match?
Find a regular expression over the alphabet that matches all strings that start with a 1, end with a 1, and have an even number of zeros between.
Wednesday, September 13
Today we mentioned the following theorem:
Theorem. A language is regular if and only if it can be represented by a regular expression.
This means that NFAs, DFAs, and RegEx’s are all equivalent to each other in terms of what they can compute. Then we looked at how to convert NFAs to RegEx’s and vice versa. We did the following examples.
- Use the ideas from last week about how to build NFAs to find the union, concatenation, and Kleene star of languages to convert to following regular expression
(ab|a)* over the alphabet Σ = {a,b} to an NFA.
Then we described an algorithm for converting NFAs to regular expressions. Note that the Maheshwwari & Smid textbook describes a different approach to convert an NFA into a regular expression in Section 2.8. We did the following example:
- Let Σ={A,C,G,T}. Convert the following NFA to a regular expression:
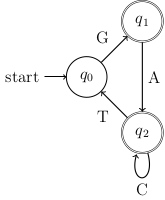
We finished today by talking about some of the short-hand and quirks in regular expression libraries for some programming languages.
Friday, September 15
Today we talked about the pumping lemma. We used the pumping lemma to prove that the following languages over Σ = {0,1} are not regular:
.
Here is a nice meme proof using the pumping lemma from Barak textbook.
Week 5 Notes
| Mon, Sep 18 |
2.9 |
Non-regular languages |
| Wed, Sep 20 |
|
Review |
| Fri, Sep 22 |
|
Midterm 1 |
Monday, September 18
Today we looked at more examples of regular and non-regular languages.
.
.
Many programming languages, including Python & Javascript allow backreferences to previous groups in a regular expression. A group is a part of the regular expression inside parentheses. The special symbol \1 refers to anything matched by the first group in the regular expression. Similarly \2 refers back to anything matched by the second group, and so on. For example: the regular expression "([a-z]*) \1" would match “word word” or “dog dog”.
- Explain why regular expressions with backreferences are not really regular expressions (at least not according to our definition).
We finished with this last example. Consider the language
Explain why there is a pumping number (in fact works) such that any string can be “pumped”.
Despite this, explain why is not a regular language.
Why doesn’t that contradict the pumping lemma?
Week 6 Notes
| Mon, Sep 25 |
3.1 - 3.2 |
Context-free grammars |
| Wed, Sep 27 |
3.3 |
Parsing and parse-trees |
| Fri, Sep 29 |
3.8 |
The pumping lemma for context-free languages |
Monday, September 25
Today we introduced context-free grammars. We started with some simple examples from Wikipedia (https://en.wikipedia.org/wiki/Context-free_grammar#Examples) to illustrate the definition.
We found a context free grammar that generates the (non-regular) language .
We looked at the example of a CFG and used it to identify the parts in the formal definition.
S → <subject> <verb>
<subject> → <article> <noun>
<article> → a | the
<noun> → boy | girl | dog
<verb> → runs | jumps | swims
Find a context-free grammar for the language .
Describe how to generate the string (a + a) * a using the context free grammar below:
<expr> → <expr> + <term> | <term>
<term> → <term> * <factor> | <factor>
<factor> → (<expr>) | a
We finished by looking at this example that gives the idea of how a programming language can be though of as a context-free language.
Wednesday, September 27
Today, we briefly went over the first midterm exam. I talked about the grading scale and went over some of the problems .
Today we spent more time discussing context free grammars. We talked about left derivations and right derivations
We looked at this example:
Use this CFG to derive the string . Try to use a left derivation. Then use a right derivation.
Show that that string actually has more than one left derivation.
A grammar is ambiguous if there are strings with more than one left derivation. If every left-derivation is unique, then the grammar is unambiguous. Note that some CFGs have unambiguous grammars, but so do not. This alternate grammar generates the same language as our first example, but is unambiguous:
<expr> → <expr> + <term> | <term>
<term> → <term> * <factor> | <factor>
<factor> → (<expr>) | a
We looked at this ambiguous grammar.
- Show that the sentence “the girl touches the boy with the flower” has two left derivations and those derivations correspond to two different meanings this sentence can have.
Friday, September 29
Today we discussed the pumping lemma for context-free languages. This is a little more complicated than the pumping lemma for regular languages. We drew some pictures of parse trees to give an intuitive explanation for why this new pumping lemma is true (see page 126 in Maheshwari & Smid). In particular, we looked at how the string a+a*a gets generated by the grammar:
E → E + T | T
T → T * F | F
F → (E) | a
In the parse tree, there is a branch where the variable T gets repeated, and that lets us “pump”.
We used the pumping lemma to prove that the following languages are not context-free:
.
.
.
We also talked about how there are always an uncountable number of languages over a finite alphabet (since the set of languages is the power set of ), and a computer can only compute a countable set of languages, so it is not surprising that most languages are not context-free.
Week 7 Notes
| Mon, Oct 2 |
3.5 - 3.6 |
Pushdown automata |
| Wed, Oct 4 |
3.7 |
Pushdown automata & context-free grammars |
| Fri, Oct 6 |
4.1 - 4.2 |
Definition of Turing machines |
Monday, October 2
Today we talked about nondeterministic pushdown automata (NDPA) which are basically just NFAs with a stack. We started with this example:
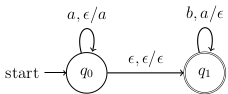
This NDPA accepts the language . Notice that each arrow has three parts, for example the first loop is labeled which means you can take this loop if you read an from the input string, and pop (i.e., nothing) from the stack, and then push onto the stack. We will always use this notation (read, pop/push) for each arc.
NDPAs work just like NFAs, except they have this extra rule: You only accept a string if you finish in an accepting state and the stack is empty.
Some things to note:
Since the machine is nondeterministic, you can have more than one state (and more than one stack) branching off whenever you have a choice about which arrow to take.
If you are in a state and there is no valid arrow to take, then that state dies.
We looked at these questions:
For the NPDA below, describe the language that it accepts.
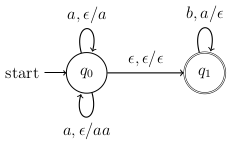
Describe an NPDA that accepts the language .
Describe an NPDA with just one state that accepts the language of balanced parentheses.
Wednesday, October 4
Today we talked about the equivalence between CFGs and NPDAs. We sketched the proof of one direction: that if you have a CFG, then there is an NPDA that accepted the same language.
The idea of the proof is to create an NPDA with three states. In state you immediately transition to reading nothing and push S$ on the stack (where $ is a special symbol to mark the bottom of the stack). Then in state you have two different types of transitions that loop back to :
Transitions where you read nothing and pop a variable off the stack, then push the output of one of the grammar rules for that variable back onto the stack. (I called these red transitions.) You have one red transition for each of the rules in the grammar.
Transitions where you read a symbol from the input and pop that symbol off the stack. (I called these blue transitions.) You have one blue transition for each of the terminals in the grammar.
Finally, you have a final transition to the accepting state which involves reading nothing and popping the $ off the stack. If you have finished reading the input when you do this, you will accept the string.
We illustrated how this idea works using the grammar and the input string aabbbb.
S → AB
A → aAb | ε
B → bB | b
We finished by describing how Deterministic Pushdown Automata (DPDAs) are different from Nondeterministic Pushdown Automata (NPDAs) and the hierarchy of different languages that we have seen so far. We looked at this example DPDA:
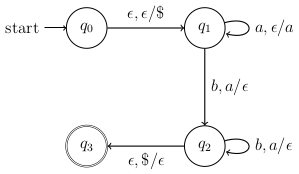
Friday, October 5
Today we introduced Turing machines (TMs) which will be the most general model of computation that we will discuss. We looked at two examples of TMs:
First we drew a state diagram for a TM that accepts the language .
Second we described an algorithm for a TM that accepts the language
We defined what it means for a Turing machine to accept or recognize a language if it accepts every string in the language. We also defined when a Turing machine decides a language, and how that is different than just accepting/recognizing. Both of the example Turing Machines above actually decide their languages, since they will successfully reject any input that doesn’t match a valid string (they won’t get stuck running forever without halting).
Week 8 Notes
| Mon, Oct 9 |
4.2 |
Turing computable functions |
| Wed, Oct 11 |
4.3 - 4.4 |
Church-Turing thesis |
| Fri, Oct 13 |
5.5 - 5.7 |
Enumerators |
Monday, October 9
Today we started with this example:
- Construct a Turing machine that reads an input string and leaves on the tape when it halts.
This wasn’t to hard to describe the algorithm, but it got a little complicated when we made the state diagram. Once we did that, we defined Turing computable functions.
Definition. A function is Turing computable if there is a Turing machine that halts with on the tape whenever it is given a tape with as input.
Explain why the function is Turing computable.
Prove that if are both Turing computable functions, then so is the composition .
Explain why the function is Turing computable. Hint: Every regular language is Turing decidable.
We finished by describing how this function (which comes up in the Collatz-Conjecture) is Turing computable:
Wednesday, October 11
Today we mentioned but did not prove that any problem that a multi-tape Turing machine can solve, can also be solved by a single-tape Turing machine. You can find a readable proof in Section 4.3 in the book.
Instead, we summarized what we know so far:
Turing machines are able to decide any regular or context-free language. That is, if is a context-free language, then the function defined by if and only if is Turing computable.
If and are Turing computable functions, then so is the composition .
If , and are Turing computable, then so is the function
IF f(x) THEN g(x) ELSE h(x).
So here is a question: Can a Turing machine have a for-loop, where it repeats some function times? Something like this Python example where function is applied times?
for i in range(n):
x = f(x)
- What about a while-loop?
I think we get the idea that you can implement pretty much all of the basic building blocks of most programming languages using Turing machines. There are many other models of computing that can be proven to be Turing complete, that is, they can compute the same functions as Turing machines. But it is believed that there is no “effective method” of computation that can solve problems that Turing machines cannot solve. The Church-Turing thesis says that an computational task that we can describe how to solve with an algorithm can be computed by a Turing machine.
We finished by discussing Hilbert’s 10th problem: Is there an algorithm to determine whether a multivariable polynomial with integer coefficients has an integer root. We looked at some example polynomials like and It turns out that no Turing machine can decide the language of integer multivariable polynomials with integer roots. But we did describe an algorithm that recognizes that language.
Friday, October 13
Today we introduced enumerators. An enumerator for a language is a Turing machines that computes a function that is onto. We started by proving the following:
“Easy” Lemma. If is decidable, then there is an enumerator for .
To prove this lemma, we came up with the following algorithm. In class I didn’t include the just_started variable which caused a minor issue in the proof.
input n
# use a decider function to return the n-th string in the language
s = ""
for i in range(n):
just_started = True
while just_started or not decider(s):
just_started = False
increment(s)
return s
“Harder” Theorem. A language is recognizable if and only if there is an enumerator for .
It was relatively easy to prove the direction as this algorithm demonstrates:
input w
# use an enumerator function to return True if w is in L
n = 0
while not w == enumerater(n):
n++
return True
The other direction is harder to prove. We sketched a proof at the board, but the important thing to understand is this: Why doesn’t the algorithm for the “Easy Lemma” prove the case of the “Harder Theorem”?
Week 9 Notes
| Wed, Oct 18 |
B9.1 |
Universal Turing machines |
| Fri, Oct 20 |
5.1-5.3 |
The halting problem & Rice’s theorem |
Wednesday, October 18
Today we introduced universal Turing machines. We use them to consider this language:
- Explain why Accept is Turing recognizable.
Then we gave a diagonalization proof that Accept is not Turing decidable. Suppose there was a decider for Accept. Then we could make a table with rows for each Turing machine and columns every Turing machine encoding and entries 1 or 0 depending on whether accepts .
What would happen if we created a TM inputs any TM encoding and then does the opposite of what does on . What would do when you input into ?
Why is that a contradiction?
We finished by observed that there are only a countably infinite number of possible Turing machines, but there is an uncountable infinite number of languages, so there must be lots of languages that are not decidable!
Friday, October 20
Today we proved that the language
is undecidable. Here is the proof:
If Halt were decidable, then we could use the following algorithm to decide if :
- Check if .
- If it is, run on and accept or reject accordingly.
- If not, then reject.
Since this algorithm would decide the language Accept from last time, but we proved that the language Accept is undecidable, we conclude that Halt must also be undecidable.
Then we proved Rice’s theorem (our book also has a proof in Section 5.3, my proof was shorter, but I glossed over some of the details). We used Rice’s theorem to prove that these two languages are undecidable.
.
.
Week 10 Notes
| Mon, Oct 23 |
|
Review |
| Wed, Oct 25 |
|
Midterm 2 |
| Fri, Oct 27 |
|
no class |
Monday, October 23
Today we reviewed that material from CFGs and NPDAs through TMs. We did some examples:
Show that there is no CFG or NPDA that can generate/accept this language: .
Find a NPDA that accepts the language .
Use Rice’s theorem to prove that the language is undecidable.
Why can’t you use Rice’s theorem to prove that the language is undecidable?
Explain why the complement of the language is uncomputable (i.e., not even recognizable).
Week 11 Notes
| Mon, Oct 30 |
6.1 |
The running time of algorithms |
| Wed, Nov 1 |
6.2 |
The complexity class P |
| Fri, Nov 3 |
6.2 |
The complexity class P - con’d |
Monday, October 30
Today we introduced big-O notation and used it to talk about running times of algorithms. Note that There are lots of important examples in Barak Chapter 12 of algorithms and their running times.
- Which is true? or ?
We proved the following facts about big-O notation:
Theorem (Only Dominant Terms Matter). If is a sum of nonnegative functions , then there is at least one function such that . We call that function a dominant term for .
Theorem (Constant Multiples Don’t Matter). For any and constant , .
Theorem (Products of Functions). If and , then .
We also reviewed this heirarchy of functions:
We used these ideas to find the dominant term for these expressions:
.
.
So why do we use big-O notation? It makes it easier to talk about a lot of formulas. For example, an algorithm that requires steps can be described simply as being .
Caution 1. Big-O notation only gives an upper bound for how fast functions grow. Functions in don’t have to grow at the same rate as , they can also grow much slower.
Caution 2. You should always write the simplest possible expression inside big-O notation. For example , so just write .
We finished by talking about how we use Big-O notation to describe the runtime of algorithms such as:
The TM from Midterm 2 that decrements a binary string by 1.
Testing whether a number (represented in binary) is prime.
Wednesday, November 1
Today we talked about the running times of some algorithms. We started with this example:
- Prove that the language can be decided in time.
We defined class P which is the set of all decidable languages for which there exists a Turing machine and a constant such that can decide in time.
Prove that if are both in P, then the concatenation is also in P.
Consider the PATH problem which involves deciding this language: Prove that the following algorithm runs in polynomial time.
- Step 1 - place a mark on node s.
- Step 2 - loop through the edges in the graph. For any edge that touches exactly one marked vertex, mark the other vertex.
- Step 3 - repeat step 2 until you can’t find any new vertices to mark.
- Step 4 - accept if t is marked, otherwise reject.
One important fact that I forgot to mention in class is the following:
Fact. If a Turing machine can decide a language in polynomial time, then so can a Python or C++ program.
Friday, November 3
Today we proved that all Context Free Languages (CFLs) are in class P. Before we proved this, we introduced the idea of Chomsky’s normal form. We looked at this example CFG
and we observed that the following grammar in Chomsky normal form is equivalent, i.e., it generates the same language.
We did not go into the details of how to convert a CFG to Chomsky normal form, but you can find details of how to do that in Section 3.4 in Maheshwari & Smid. Instead, we did the following workshop which let us figure out the running time of an algorithm to decide whether a string of length can be generated by a grammar in Chomsky normal form.
Week 12 Notes
| Mon, Nov 6 |
6.3 |
The complexity class NP |
| Wed, Nov 8 |
6.4 |
Nondeterministic TMs |
| Fri, Nov 10 |
6.5 |
The SAT problem |
Monday, November 6
Today we introduced class NP. A language is in class NP if there is a solution string for every and an algorithm called a verifier that accepts in polynomial time in the length of . We looked at the following examples:
COMPOSITE .
TRIANGLE .
In each of these examples, you need to prove that if you are given a special string called the solution, then you can find a polynomial time algorithm that will use the solution to verify that a string is in the language.
We also proved this theorem:
Theorem. P NP.
Along the way, we mentioned some interesting new results:
- 2019 Harvey & van der Hoeven Multiplication Algorithm .
- 2003 Agarwal, Kayal, Saxena (AKS) Primality Test - polynomial time algorithm.
It is still unknown whether P NP.
Wednesday, November 8
Today we talked about what the name NP stands for. It refers to problems that are solvable in polynomial time by a nondeterministic Turing machine. We defined nondeterministic Turing machines, and then we proved the following:
Theorem. Any language that can be decided (or recognized) by a nondeterministic TM can be decided (recognized) by a TM.
Theorem. A language is in class NP if and only if there is a nondeterministic TM that decides in polynomial time.
Friday, November 10
Today we introduced the Boolean satisfiability problem (SAT). Recall that a Boolean formula/circuit (involving AND, OR, and NOT gates) can evaluate any function . For example, is a Boolean formula/circuit. The Boolean satisfiability problem involves deciding if a Boolean formula can be satisfied. That is, if there are values of the input variable that can make the output TRUE. In other words, we want to decide if a Boolean formula is in the language
Give an example of a Boolean formula that is not satisfiable.
Prove that SAT is decidable.
A Boolean formula is in conjuctive normal form (CNF) if it combines a finite number of clauses made by connecting literals (either variables or negated variables) with AND statements, and then the clauses are all joined together by OR statements. For example
is in CNF.
An important special case of the SAT problem is the 3SAT problem, which only looks at Boolean formulas in CNF where the clauses each involve only 3 literals. So a 3-CNF formula would be something like:
- If a Boolean formula has -variables, then how many different 3-clauses are possible?
Instead of using a brute force algorithm to decide 3SAT, we will take a different approach and prove that solving the 3SAT problem is not much harder than deciding this language:
- Prove that CLIQUE is in class NP.
The key to link 3SAT and CLIQUE is to draw a graph where every vertex corresponds to a literal in one of the clauses, and we draw edges according to the following rules:
- Never draw an edge connecting literals in the same clause.
- Always draw an edge connecting literals in different clauses, unless they are negations of each other.
Then, if a Boolean formula in 3-CNF has -clauses, then it is decidable iff the corresponding graph has a -clique (as the following image illustrates):
 3-satisfiability
3-satisfiability
Week 13 Notes
| Mon, Nov 13 |
6.5 |
Polynomial time reductions |
| Wed, Nov 15 |
6.5 |
Hamilton path problem |
| Fri, Nov 17 |
6.5 |
NP-Complete languages |
| Mon, Nov 20 |
|
TBA |
Monday, November 13
Today we introduced polynomial time reductions.
Definition. A language is polynomial-time reducible (or polyreducible) to language (denoted ) if there is a function such that
- , i.e., can be computed in polynomial time, and
- if and only if .
We started by proving that SAT 3SAT. To prove that we considered the following transformation:
For any clause , you can replace the last two literals by a dummy variable and then add another clause with and the two literals you removed.
Explain why this transformation will preserve whether or not a boolean formula in CNF is satisfiable.
Explain why this transformation can be computed in polynomial time.
We looked at this theorem:
Theorem. If and is in class-P, then so is .
- Give an algorithm proof for this theorem.
We also proved that 3SAT CLIQUE by looking at how long it takes to construct the graph in the example from last class. We finished by defining NP-complete.
Wednesday, November 15
Today we went over Homework 10. We didn’t cover any new material, but we did introduce the following language:
So FIB contains .
Then we asked whether the following decimal strings are in FIB:
We also determined that FIB P since the following algorithm runs in less than time:
Fib = [1,1]
while w < Fib[-1]:
Fib.append(Fib[-2]+Fib[-1])
if w == Fib[-1]:
return true
else:
return false
Friday, November 17
Today I started by announcing this extra credit project. You can do it on your own, or bring your laptop to class on Monday and we’ll work on it then.
Then we introduced the classes NP-complete and NP-hard.
Definition. A language is NP-complete if
- , and
- Every other NP language has a polynomial-time reduction to . (i.e., ).
Any language satisfying property 2 is called NP-hard whether or not it satisfies property 1.
We prove that the relationship (polynomial-time reducibility) is transitive, and used that to prove this theorem:
Theorem. If and is NP-Hard, then so is .
- Prove that if and , then .
We finished by talking about the Cook-Levin theorem
Theorem (Cook-Levin). SAT is NP-complete.
We sketched a proof. First we observe that for any there is a polynomial time verifier that can decide if with the help of a solution string . Assuming that both and are encoded in , we can reduce the question of whether to a question about whether there is a solution such that accepts . If we think of as fixed, then the question of whether there is a solution is equivalent to asking whether the Boolean function
is satisfiable.
Since that question is a Boolean function , there is a Boolean formula involving AND, OR, and NOT for . We just have to prove that we can construct that formula in polynomial time.
To prove that you can construct a formula for in polynomial time, observe that only has a finite number of states which can be described by a state string . There is also exactly one position on the tape that the head is pointing to at a time. Call that position the head variable . Since at each step reads the head variable, writes a new value for the head variable and then moves to a new state, while moving the head variable left or right on the tape, you can create a Boolean formula to simulation the action of one step of on and in constant time. Then each step will correspond to a different Boolean formula with the same state variable but possibly different head variables. After steps, the verifier will accept or reject, so we can create a Boolean formula to simulate in time.
Monday, November 20
Today we talked about homework 11. We also talked about the extra credit project. In particular, I suggested that the following hint might help write an algorithm to solve problem 3 from homework 10:
The algorithm to decide if only needs to loop through substrings of that start at the beginning of .
To decide if a substring that starts at the beginning of is in , just check two things:
- First, is the substring in ?
- If not, then is the substring a combination where and ?
Week 14 Notes
| Mon, Nov 27 |
|
review |
| Wed, Nov 29 |
|
Midterm 3 |
| Fri, Dec 1 |
|
|
| Mon, Dec 4 |
|
|
Monday, November 27
Today we focused on review for the midterm on Wednesday. The midterm will cover the following topics:
- Big-O notation
- You should be able to describe simple polynomial time algorithms and identify the Big-O run-time for an algorithm involving loops.
- Classes P vs. NP
- understand the definitions of these two classes.
- For NP languages, you should be able describe a verifier algorithm and explain why it runs in polynomial-time.
- Should also understand the difference between a verifier algorithm and a nondeterministic polynomial-time decider.
- Polynomial time reductions
- understand polynomial-time reductions and be able to describe simple examples.
- NP-complete & NP-hard
- understand the definitions and be ready to prove basic facts like what was in the homework.
- SAT problem & Cook-Levin theorem
Factoring large integers is hard (it can be done in nondeterministic polynomial time, but most computer scientists believe it cannot be done in polynomial time). For example, the integer 82264459 factors as (9049)(9091). Explain the difference between a function that factors an integer and a function that can verify if a factorization is correct. What would the two functions input? Why would the later function definitely run in polynomial time even if the first function cannot?
A language is in class EXP if it can be decided in time for some integer . Prove that . Note: It is an open problem whether or not .
Explain why the problem of finding the median entry in an array of integers is polynomial time reducible to the problem of sorting an array of integers.
We also reviewed some of questions from HW11. In particular, we talked about problem #4 and how you can write a polynomial time nondeterminsitic algorithm by including a random number generator in your pseudocode. Then if any of the random results accepts the input, then the whole algorithm does.
Friday, December 1
Today we reviewed the Chomsky heirarchy of languages, and we looked at how the different complexity classes (P, NP, EXP) fall in that heirarchy. We also review problem 2 from the midterm. We also did the following exercise in class:
- Prove that is NP-Hard.
Monday, December 4
We reviewed some of the material we haven’t seen in a while. We looked at these questions.
Consider the regular expression 1(0|1)*(+|-)1(0|1)*. What language does this regular expression represent? Give a simple description of the strings in that language.
Create an NFA that recognizes that language.
Since the language is regular, it is also context free. Create a context free grammar that generates the language.
Consider the language . Prove that this language is not context free. (Use the pumping lemma for CFLs).
Show that the language from the previous problem is decidable by describing a Turing machine algorithm that can decide . What is the run-time for that algorithm in big-O notation?
What is an example of a language that is context free but not regular?
Describe an NPDA that recognizes your language from the previous question.
{kind=link}
{kind=link}